Data collection
To build CORP, images are captured at a rate of 20 Hz while maintaining GPS time synchronization. Simultaneously, the LiDAR data is acquired at 10 Hz with the same source for recording timestamps. Each episode of the time sequence data in CORP lasts for 30 to 32 seconds with image and LiDAR frames from multiple sensors, the quantity of which varies across different regions. Subsequent to data collection, a precise alignment between the camera and the LiDAR timelines is performed in a post-processing manner with a tolerance of 20 milliseconds, to arrive at a final frame rate of 10 Hz for the data episodes. For scene diversity and considering the specificity of the campus environment, we select the data based on sparsity of the scene and get an average of 10 targets per LiDAR frame. Moreover, around 20% of the data frames are recorded in the evening and 80% in the daytime including morning, noon, and dusk with clear and cloudy weather conditions. The diversity within the CORP dataset would enable the robustness of perception algorithms to various campus-specific backgrounds and lighting conditions. Some samples in the dataset with their ground-truch annotations are shown below.
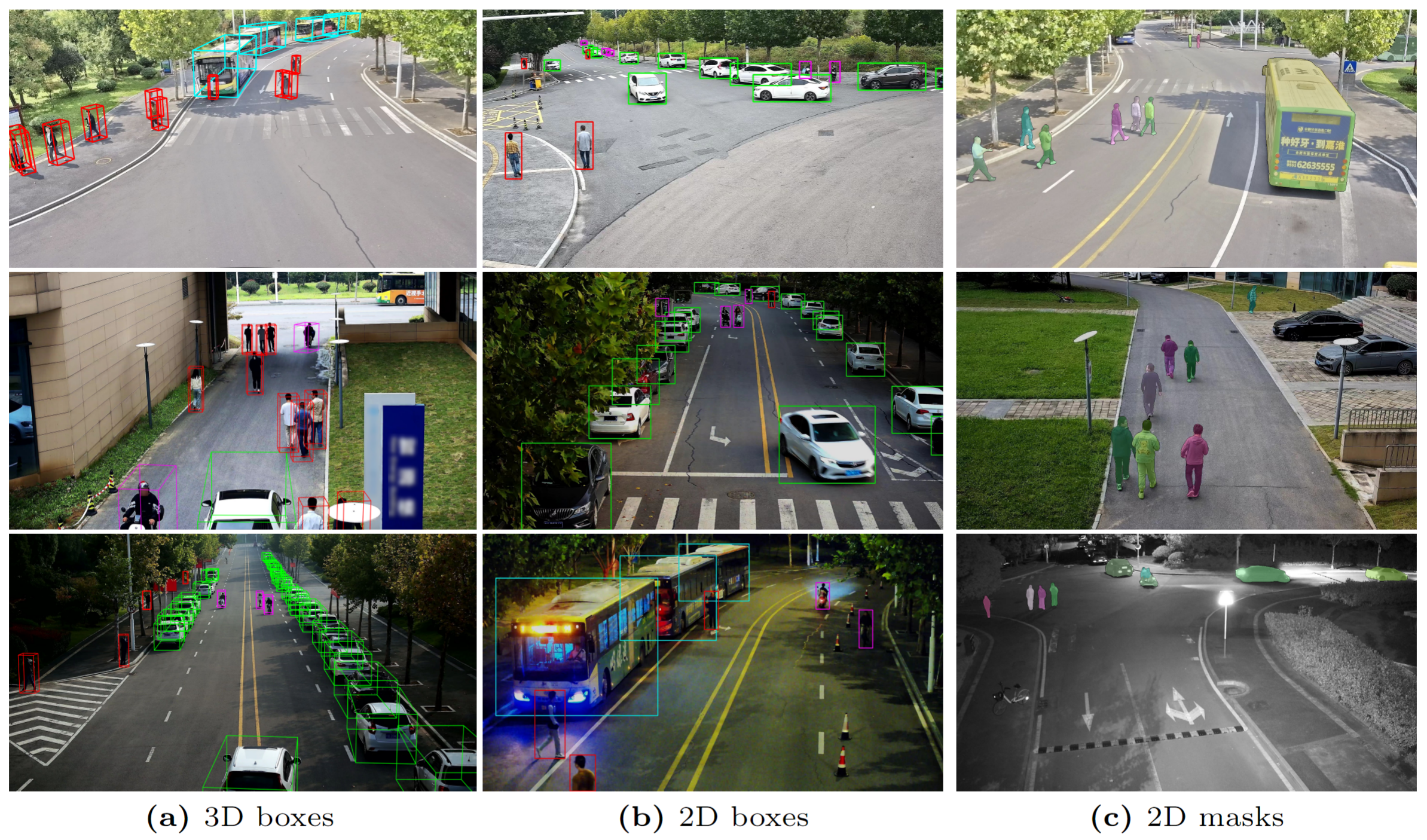
Annotation Format
Coordinate Systems
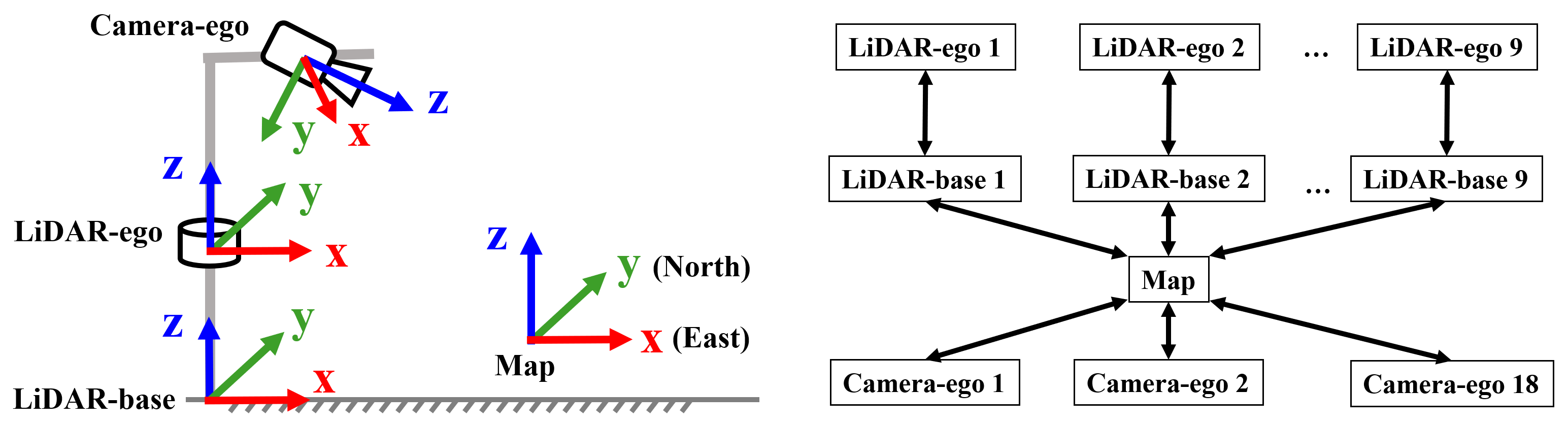
We have constructed four types of coordinate systems for the CORP dataset, of which two are used for LiDAR sensors, one for cameras, and the last one for the global map, as illustrated in Fig. 4. For LiDARs, the LiDAR-ego reference frame originates from the sensor itself with the x-axis pointing forward and z-axis upward. For the convenience of researchers and to safeguard data privacy, we have constructed an additional virtual LiDAR coordinate system, termed as LiDAR-base, by transforming the origin of LiDAR-ego to the ground contact point of its host pole to comply its x-o-y plane with the local ground surface. For cameras, the origin of the camera-ego coordinate system overlaps the optical center of the sensor with the z-axis pointing forward along the camera's view and x-axis pointing leftward accordingly. While the LiDAR and camera coordinate systems capture objects in the sensor's field of view, the Map integrates the objects into a coherent global representation, aligning the x-axis with the eastern direction and the y-axis parallel to the northern direction, employing an origin anchored at a precisely determined set of GPS coordinates.
3D annotations:
The annotation file is similar to the DAIR-V2X-i format and store in JSON file.
[
{
"type": <str> -- type of the target.
"id": <str> -- tracking id
"status": <str> -- motion status
"3d_dimensions": <> -- size of the 3d bounding box.
{
"h": <str> -- height of the box.
"w": <str> -- width of the box.
"l": <str> -- length of the box, which is measured along the heading direction.
},
"3d_location":<> -- location of the center of the 3d bounding box.
{
"x": <str> -- x coordinate.
"y": <str> -- y coordinate.
"z": <str> -- z coordinate.
},
"rotation": <str> -- heading angle, relative to x axis, increasing in a counter-clockwise manner
},
{
...,
}
]
2D annotations:
[
{
"type": <str> -- type of the target.
"id": <str> -- tracking id.
"occluded_state": <str> -- occlusion status.
"truncated_state": <str> -- truncation status.
"status": <str> -- motion status.
"2d_box": <str> -- location and size of the 2d bounding box.
{
"xmin": <str>
"ymin": <str>
"xmax": <str>
"ymax": <str>
}
},
{
...,
}
]
Semantic Labels
There are 5 different target categories and 2 motion status for sementic attributes for 2D/3D targets.
- For object type: Bus, Car, Pedestrian, Bicycle, Tricycle
- For motion state: Moving, Static
Instructions
We will release the development tookit for data visualization, model training and evaluation soon on our project page.
Download
Download links for CORP dataset:
- Labeled subset: [Available Soon]
- Unlabled subset: [Available Soon]